|
Getting your Trinity Audio player ready...
|
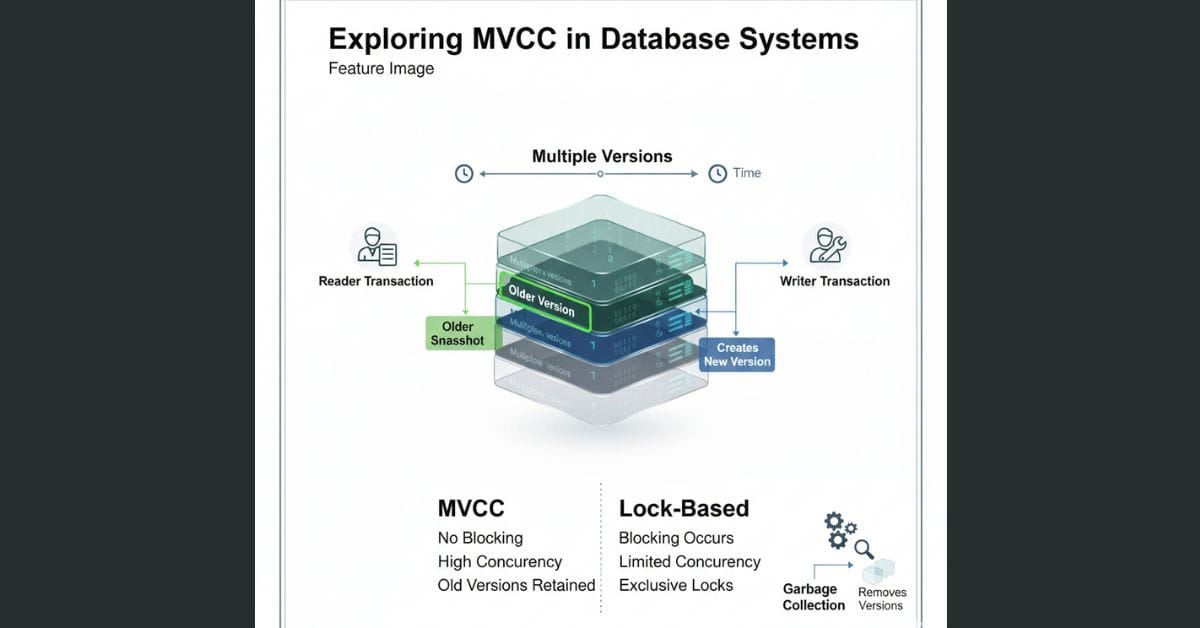
MVCC (Multi-Version Concurrency Control) is a concurrency control technique used by modern databases.
It allows multiple transactions to read and write data at the same time.
Without blocking.
This is done using multiple versions of the same data.
What Problem MVCC Solves
Traditional locking causes waits. Readers block writers. Writers block readers. Performance drops fast.
MVCC removes most of this blocking. Each transaction works on its own snapshot.
How MVCC Works
Transactions do not overwrite data. They create new versions.
MVCC Snapshot View
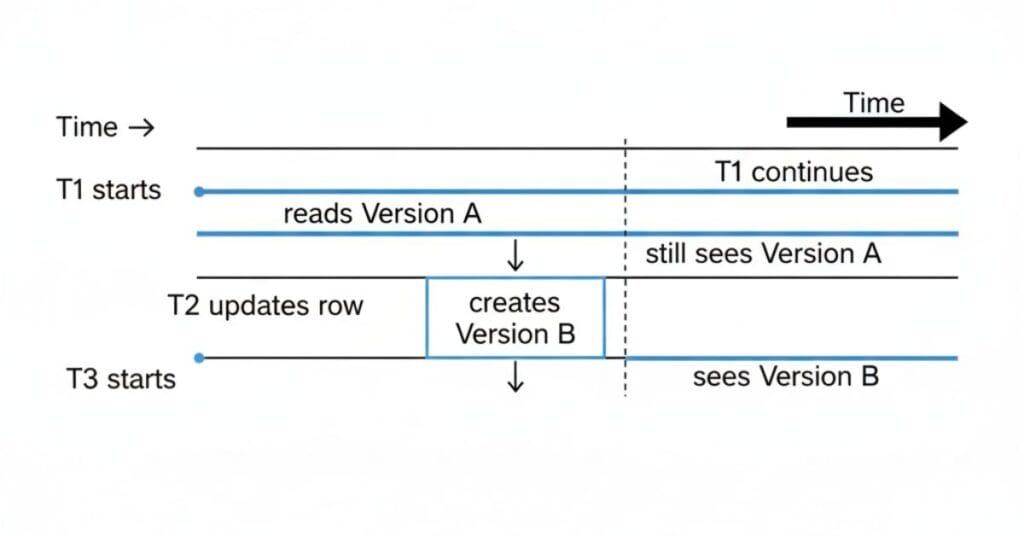
Each transaction only sees data committed before it started.
Core MVCC Components
MVCC works using these core building blocks.
| Component | Purpose |
|---|---|
| Transaction ID | Identifies transaction order |
| Row Versions | Stores multiple states of data |
| Snapshot | Defines visible data |
| Garbage Collection | Removes unused versions |
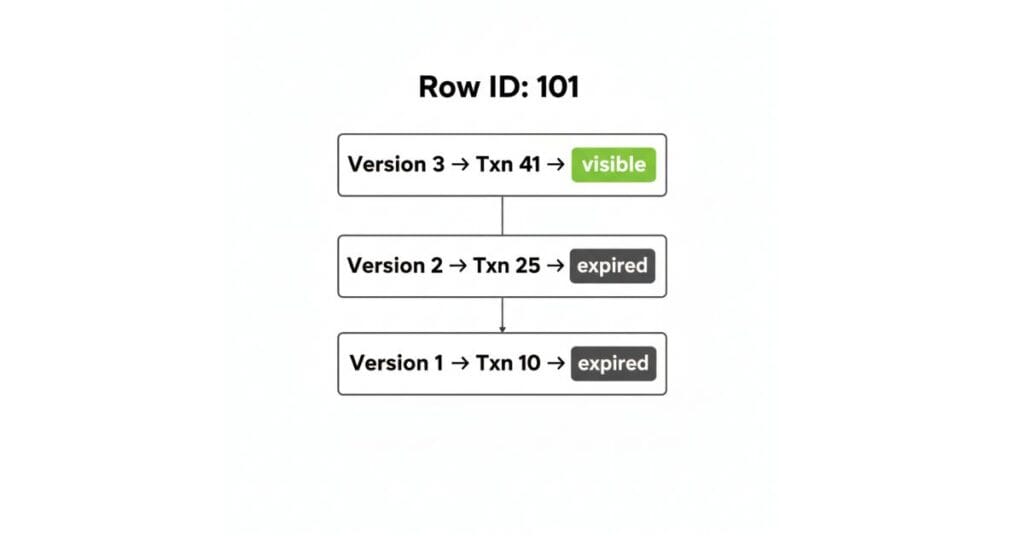
Row Versioning Model
MVCC vs Lock-Based Concurrency
Lock-based systems block. MVCC does not.
| Feature | MVCC | Lock-Based |
|---|---|---|
| Reader blocking | No | Yes |
| Writer blocking | No | Yes |
| Concurrency | High | Limited |
| Deadlock risk | Low | High |
Read vs Write Without Blocking

MVCC in Popular Databases
| Database | MVCC Implementation |
|---|---|
| PostgreSQL | Row versioning with vacuum cleanup |
| MySQL (InnoDB) | Undo logs for older versions |
| Oracle | Rollback segments |
| SQL Server | Snapshot isolation with row versioning |
Advantages of MVCC
- Non-blocking reads
- Better throughput
- Scales well under load
- Ideal for read-heavy systems
Trade-offs of MVCC
MVCC is not free.
- Higher storage usage
- Cleanup overhead
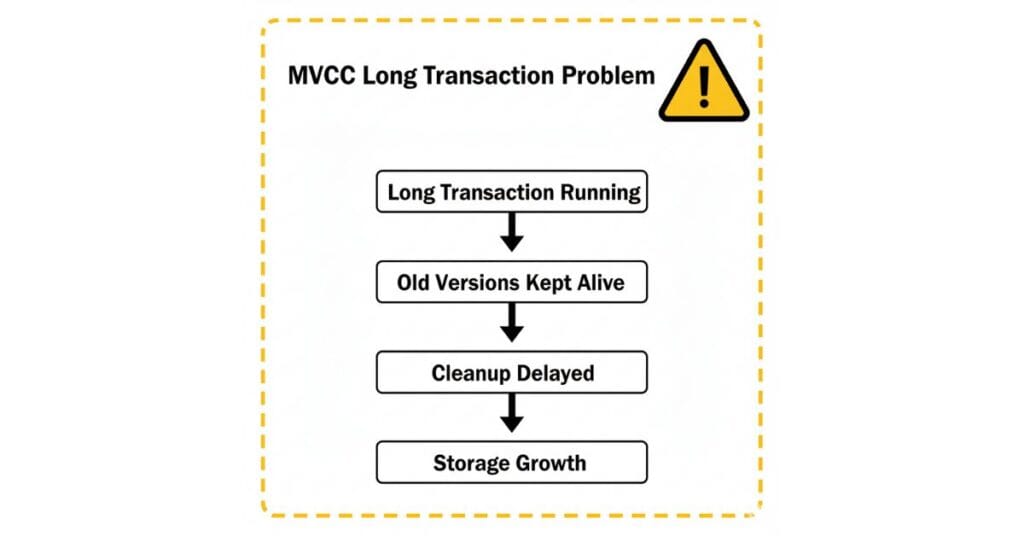
- Long transactions cause issues
Garbage Collection Lifecycle

Long Transaction Problem
When MVCC Works Best
- OLTP systems
- Web applications
- APIs with high concurrency
- Systems with frequent reads
FAQs
Is MVCC the same in all databases?
No. Each database implements MVCC differently. The concept is shared. The internals are not.
Does MVCC remove locks completely?
No. Write conflicts still use locks. MVCC mainly avoids read locks.
Why do long transactions cause problems?
They keep old versions alive. Cleanup cannot run. Storage usage increases.
Is MVCC good for write-heavy workloads?
It helps. But extreme write contention still causes conflicts.
Final Take
MVCC is a foundation of modern databases. It improves concurrency. It avoids blocking.
It trades storage for speed. For scalable systems. MVCC is hard to ignore.

Arsalan Malik is a passionate Software Engineer and the Founder of Makemychance.com. A proud CDAC-qualified developer, Arsalan specializes in full-stack web development, with expertise in technologies like Node.js, PHP, WordPress, React, and modern CSS frameworks.
He actively shares his knowledge and insights with the developer community on platforms like Dev.to and engages with professionals worldwide through LinkedIn.
Arsalan believes in building real-world projects that not only solve problems but also educate and empower users. His mission is to make technology simple, accessible, and impactful for everyone.
Join us on dev community

